

TurboQuant Explained: Extreme AI Compression for Faster, Cheaper Models
Hitesh Sondhi · April 24, 2026 · 7 min read
Google dropped TurboQuant, and a lot of teams read the headline like it was magic: smaller models, faster inference, lower bills. We’ve seen this movie before. Someone hears “extreme compression,” pushes quantization too far, and by Friday they’ve got a cheap model that answers like it got three hours of sleep and half the context window.
That’s the part people skip.
TurboQuant is interesting because it pushes the conversation past boring “8-bit is good” advice and into a messier engineering reality: how far can you squeeze a model before it stops being useful? If you care about latency, GPU memory, edge deployment, or serving costs, this isn’t academic. This is budget, UX, and pager-duty.
Key Takeaways
- TurboQuant matters because extreme compression can cut inference cost and deployment size without requiring a totally new model stack.
- But aggressive **AI model compression** always comes with tradeoffs: [accuracy drift](/blog/ai-agent-evaluation), brittle outputs, and [harder evaluation](/blog/ai-agent-evaluation-framework).
- Quantization helps most when memory bandwidth is your bottleneck, not when your whole pipeline is already slow for other reasons.
- For voice and edge products, smaller models often beat bigger “smarter” ones that can’t ship reliably.
- You shouldn’t adopt extreme compression because it’s trendy. You should adopt it because your benchmarks say it survives your workload.
Why TurboQuant got everyone’s attention
The broad idea behind TurboQuant is simple: represent model weights more efficiently so the model takes less memory and can run faster. That sounds like standard quantization, and in one sense it is. But the point of the announcement is that Google is pushing harder on extreme compression, where the engineering question stops being “can we quantize?” and becomes “can we still trust the output after we do?”
Here’s the hot take: most teams don’t have a model problem. They have a systems problem.
We’ve watched teams obsess over shaving bits off weights while ignoring the fact that their retrieval step is sloppy, their prompt is bloated, and their serving stack is doing unnecessary work. That’s like putting racing tires on a van with a broken transmission. AI model compression is powerful, but it won’t save a bad architecture.
For context, Google Research framed TurboQuant as a way to improve efficiency for LLM inference and deployment workloads Google Research Blog. The exact implementation details matter less for most product teams than the practical implication: if compression gets more aggressive without wrecking quality, the economics of serving models change fast.
That’s where it gets interesting.
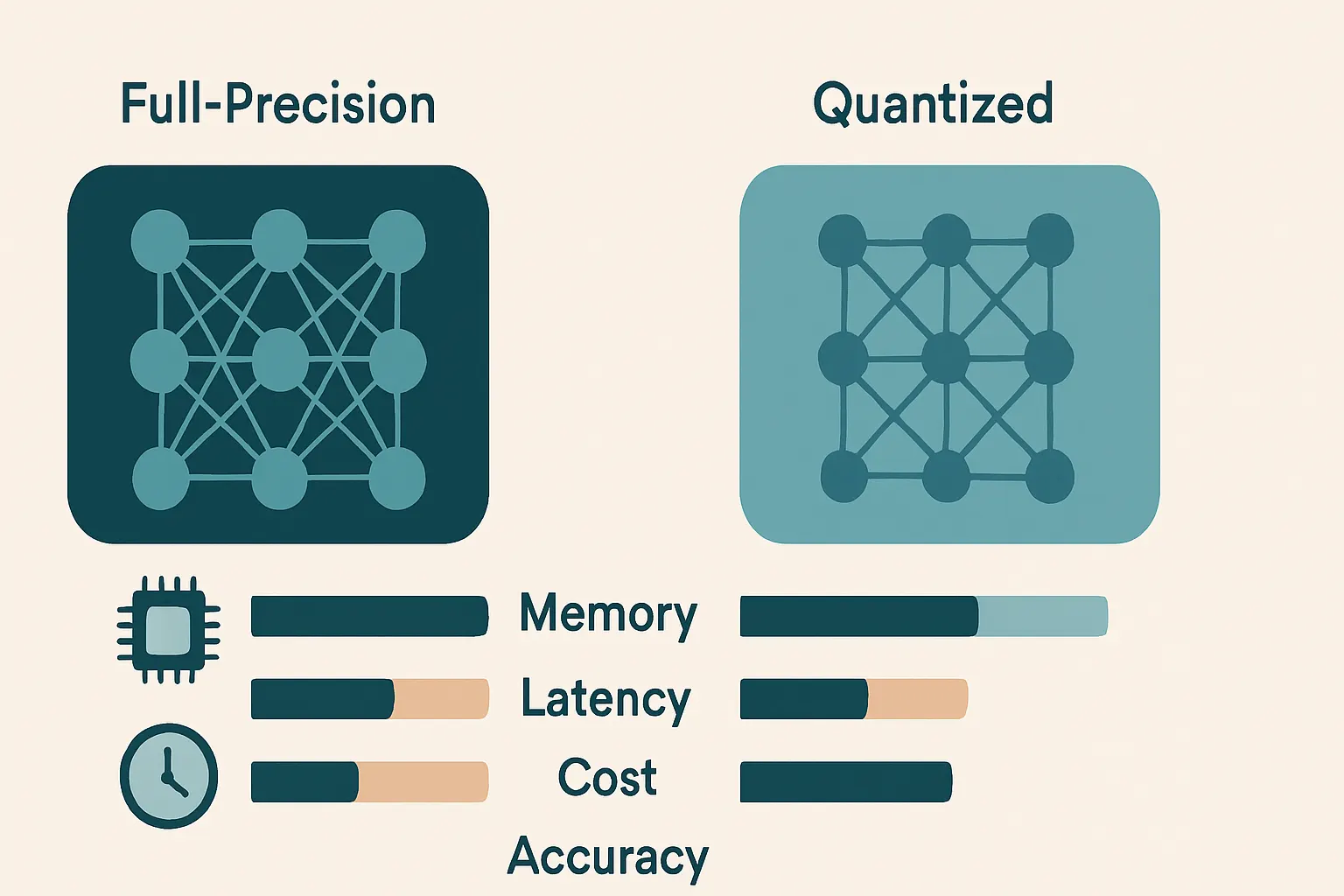
Here’s the mental model: quantization is like packing for a two-week trip with one carry-on. Fold well, remove junk, and you’re fine. Vacuum-seal everything like a maniac, and now your dress shirt looks like it lost a fight.
What extreme AI compression means in practice
When people say AI model compression, they usually mean some mix of quantization, pruning, distillation, or low-rank tricks. In production, quantization gets the most attention because it directly attacks the two things infra teams hate paying for: memory and compute.
A compressed model can mean:
- Lower VRAM usage, so you can fit larger workloads on cheaper hardware
- Faster inference, especially when memory movement is the bottleneck
- Smaller artifacts, which helps with edge rollout and cold starts
- Lower serving cost over time if quality holds up
If you’re building for edge or private environments, this matters even more. We care about this a lot in /services/on-device-ai and /services/voice-ai because shipping a model that barely fits is usually a mistake. A model that’s 10% smarter on paper but misses your latency target in the real world is not smarter. It’s unemployed.
Here’s a simple way to think about the tradeoff:
flowchart TD
A[Start with full-precision model] --> B[Apply quantization]
B --> C[Smaller memory footprint]
C --> D[Faster and cheaper inference]
B --> E[Quality evaluation]
E --> F{Accuracy holds?}
F -->|Yes| G[Deploy in production]
F -->|No| H[Back off compression or fine-tune]
The real surprise comes when you test it.
Some workloads tolerate aggressive compression beautifully. Classification, ranking, constrained extraction, and narrow-domain assistants often survive more than people expect. Open-ended reasoning, multilingual nuance, long-context synthesis, and tool use can get weird fast. Not broken. Weird. And weird is dangerous because it slips through shallow evals.
Why standard benchmarks can lie to you
This is where teams get burned.
A compressed model can look fine on benchmark summaries and still fail in your actual product. We’ve found that the failure modes are often subtle: worse instruction-following on edge cases, more confident wrong answers, degraded formatting, or higher error rates on low-frequency intents.
That’s why “it still scores well” isn’t enough.
You need task-level evaluation tied to your product. If you’re running customer support, test escalation accuracy. If you’re building agents, test tool-call correctness and retry behavior. If you’re shipping voice, test interruption handling and noisy-input robustness. Compression changes behavior, not just speed.
We’ve seen the same pattern with custom deployments: the best compression strategy depends on what the model actually does all day. That’s why /services/custom-models and /services/ai-consulting usually start with profiling and eval design, not with someone yelling “quantize it.”
When TurboQuant-style compression is actually worth it
Use extreme compression when deployment constraints are real, not hypothetical.
Good reasons:
- You need lower inference cost at scale
- You’re deploying on limited hardware
- You need faster response times for a user-facing app
- You’re trying to make /services/ai-agents or /products/runhotel viable on tighter compute budgets
Bad reason:
- You saw a research thread and got excited.
If your current bottleneck is prompt bloat, retrieval quality, network overhead, or poor batching, compression might help less than you think. Before touching the model, run the numbers. We built tools like /tools/ai-cost-estimator for exactly this kind of sanity check.
And yes, you can overdo it. Extreme AI model compression is one of those ideas that looks brilliant right up until the model starts shaving off the exact capabilities your product depends on.
FAQ
What is AI model compression?
AI model compression is the process of reducing a model’s size or computational requirements while trying to preserve useful performance. Common methods include quantization, pruning, and distillation.
How does quantization make AI models more efficient?
Quantization makes models more efficient by storing weights and sometimes activations with fewer bits. That reduces memory use and can speed up inference, especially on hardware where memory bandwidth is the limiting factor.
What is TurboQuant and how is it different from standard quantization?
TurboQuant is Google Research’s push toward more aggressive, efficiency-focused quantization for model inference and deployment Google Research Blog. The practical difference is that it focuses on extreme compression territory, where the gains can be bigger but the quality risks also get sharper.
Does extreme compression reduce model accuracy?
Yes, it can. Some tasks hold up surprisingly well, but others lose instruction fidelity, reasoning quality, or robustness on edge cases. You need workload-specific evaluation, not just generic benchmarks.
When should companies use compressed AI models in production?
Companies should use compressed models in production when latency, hardware limits, or inference cost are real constraints and the compressed model passes product-specific tests. If you’re not measuring business-critical behavior, you’re guessing.
What to do next
If you’re considering TurboQuant-style compression, don’t start with the compression method. Start with your bottleneck, your eval suite, and your failure tolerance.
Then test the smallest model that still does the job.
If you want help figuring out whether compression, on-device deployment, or a different architecture is the smarter move, talk to us at /contact. We’d rather save you from a bad quantization decision now than help clean it up after your model starts confidently hallucinating in production.


