


PII Still Leaks in RAG Because Masking Happens Too Late
Hitesh Sondhi · June 23, 2026 · 12 min read
We’ve seen teams build a perfectly respectable RAG stack, add output masking at the end, and then act surprised when private data still leaks. That’s like installing a smoke detector after the kitchen already caught fire.
The ugly truth is simple: if your retrieval system can fetch sensitive data, your model has already touched it. By the time you’re doing output-stage filtering, you’re not preventing exposure. You’re doing cleanup after the spill.
That’s the core reason why output-stage pii masking is the wrong defensive surface in RAG systems. And yes, “wrong” is the right word here.
The argument isn’t theoretical. The source article that sparked this conversation makes the same point clearly: output masking doesn’t stop data exfiltration if the sensitive content has already entered the model context Hashevolution on DEV.
Key Takeaways
- If PII reaches retrieval or prompt context, you’ve already widened your blast radius.
- Output masking is useful as a last guardrail, but it’s a bad primary control.
- Safer RAG starts earlier: ingestion redaction, metadata-based retrieval controls, and policy enforcement before generation.
- Leakage evals should be part of every release, not a compliance afterthought.
- If you need strong privacy guarantees, design your pipeline so the model never sees what it shouldn’t.
Output Masking Sounds Sensible. That’s Why It’s Dangerous.
On paper, masking looks responsible.
You let the model generate an answer, then run a detector over the output to hide names, emails, phone numbers, account IDs, whatever counts as sensitive for your business. That’s basically what people mean when they ask “what is PII masking?” It’s the process of obscuring personally identifiable information so it isn’t exposed to unauthorized users.
Fine. Useful. Necessary, even.
But in RAG, this becomes a trap.
Because the real security boundary isn’t the final string sent to the user. The real boundary is what the system retrieves, what gets packed into context, what tools can access, and what policies govern that path. If your retriever pulls a customer support note with full address, passport number, and billing dispute history, the model has already had access to all of it before your output filter starts playing hall monitor.
That’s not defense in depth. That’s denial in depth.
The Hashevolution piece nails this: output-stage masking protects the presentation layer, not the retrieval or reasoning layer Hashevolution on DEV. If the model can reason over sensitive content, summarize it, infer from it, or route it through tools, you’ve already lost control of the important part.
Here’s Where RAG Security Actually Breaks
We’ve found that teams usually imagine leakage as one obvious failure mode: “the model prints a social security number.”
That’s the cartoon version.
Real leaks are messier. The model paraphrases a medical note. It confirms whether a person exists in the database. It summarizes a complaint tied to a unique individual. It answers a question that should’ve been blocked by access policy, even if it never emits the exact original string.
That’s why output masking alone is overrated. It catches some literal patterns. It often misses semantic leakage.
Here’s how the failure usually unfolds:
flowchart TD A[User query] --> B[Retriever fetches chunks] B --> C[PII enters prompt context] C --> D[LLM reasons over sensitive data] D --> E[Output masking runs] E --> F[User still gets leaked meaning or inferred facts]
The model doesn’t need to quote the secret to leak the secret.
That’s the part people hate hearing.
Why Output-Stage PII Masking Misses the Real Threat
There are four reasons this goes sideways fast.
1. The model has already seen the data
Once sensitive data is in the prompt, it can influence the answer even if the exact tokens get masked later. You can redact “[email protected]” from the final response and still leak, “the customer who filed the chargeback last Tuesday from Berlin.”
Same fact. New wording. Same problem.
2. Retrieval is the bigger attack surface
Most RAG leaks start upstream. Bad chunking. Missing document-level ACLs. No tenant isolation. Metadata filters that are optional instead of mandatory. We’ve seen systems where the vector DB was treated like a magical neutral warehouse. It’s not. It’s a loaded weapon with cosine similarity.
Hot take: insecure retrieval is a bigger problem than hallucination for enterprise RAG.
Hallucinations embarrass you. Retrieval leaks get legal involved.
3. Masking engines are brittle under context
Regex-based masking is good at obvious formats. It’s bad at edge cases, multilingual data, OCR noise, weird spacing, and domain-specific identifiers. ML-based detectors are better, but they still have false negatives and false positives.
And false positives have a cost too. If your masking system turns every invoice number, hotel room number, and internal ticket ID into [REDACTED], your app becomes unusable. Security controls that wreck usability don’t survive contact with product teams.
We’ve tried over-aggressive redaction in prototypes. It was a disaster. The assistant became technically compliant and practically useless.
4. Agents and tools make this worse
If your RAG system can call tools, query APIs, or chain reasoning steps, output masking becomes even weaker as a primary defense. The leak might happen through a downstream tool call, a log, a trace, a cache, or a debug event before the final answer is ever shown.
That’s why teams building AI agents need to think in terms of data flow controls, not “final answer cleanup.”
The Better Strategy: Stop Sensitive Data Earlier
If you want real protection, move controls left.
Earlier in the pipeline. Closer to the source. Before retrieval. Before prompting. Before generation.
Here’s the architecture we’d trust.
First, classify and redact at ingestion. If a field never needs to be searchable in raw form, don’t embed it in raw form. Replace it with a surrogate token, hashed reference, or structured placeholder. Keep the original in a separate secure store with narrow access.
Second, enforce retrieval policy before vector search results ever reach the model. ACLs shouldn’t be “best effort.” They should be mandatory filters on every query path.
Third, apply prompt assembly rules. Even if a chunk is retrievable, it may not be promptable for a given user or use case.
Fourth, keep output masking as the last safety net, not the first wall.
Here’s what that looks like in practice:
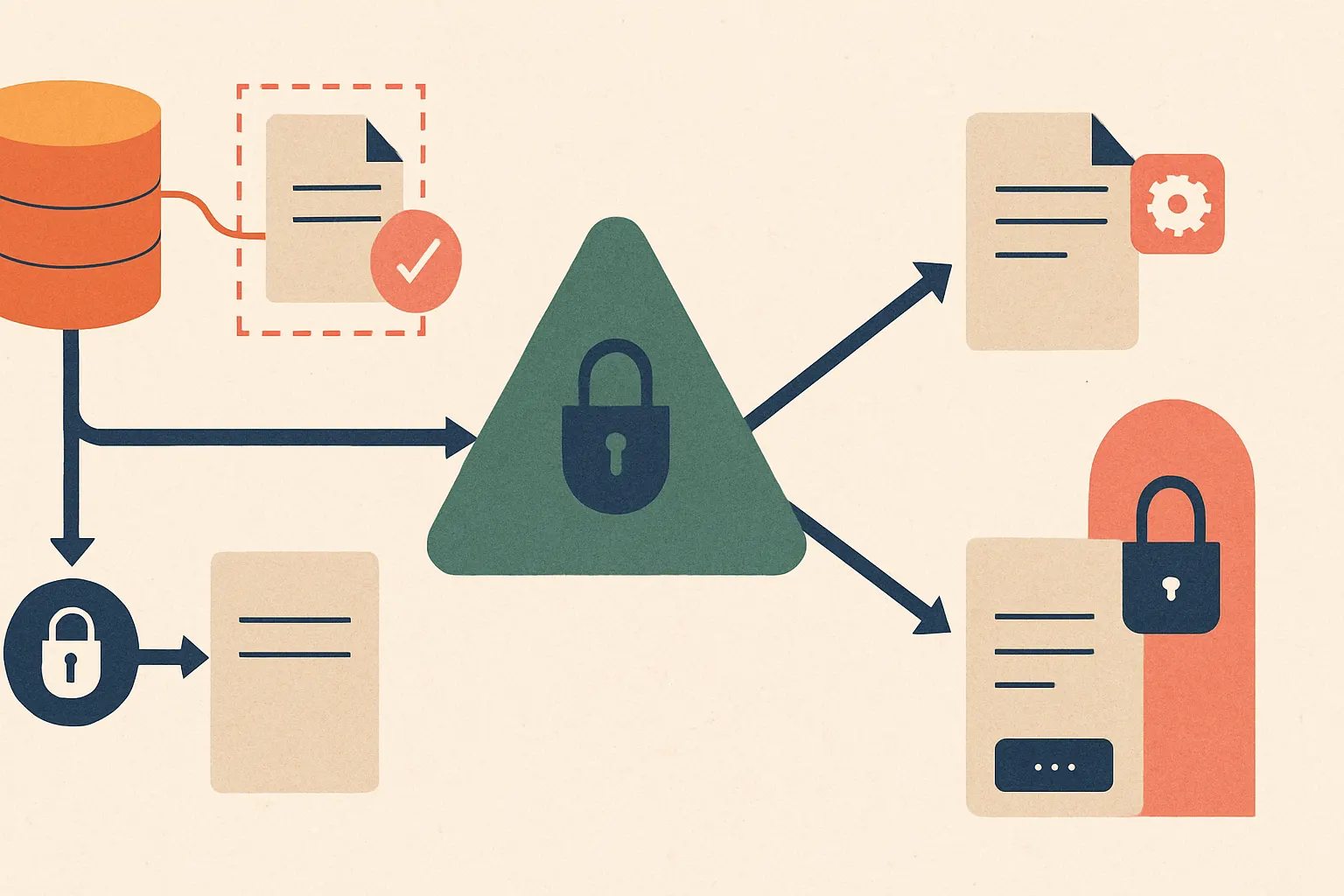
A lot of teams skip ingestion-time redaction because it feels annoying. It is annoying. So is a breach review.
Redaction at Ingestion Beats Cosmetic Redaction at the End
This is where the argument gets concrete.
If your corpus contains CRM exports, support tickets, contracts, transcripts, or medical notes, you should decide at ingestion time which fields should be:
- removed entirely
- tokenized or pseudonymized
- stored separately from embeddings
- tagged with sensitivity metadata
- blocked from retrieval except under explicit policy
That one design choice changes everything.
For example, if customer emails don’t need semantic search value, strip them before embedding. If account IDs are operationally necessary, replace them with stable surrogate references and resolve them only in a secure post-processing layer when the requesting user is authorized.
Think of it like restaurant prep. You don’t wait until the plate is on the table to decide whether the dish contains peanuts. You control ingredients in the kitchen.
Same idea.
This is especially important in systems like voice AI or on-device assistants, where transcripts can contain a shocking amount of accidental PII. In products like RunHotel, voice interactions can surface names, room details, booking references, and payment-related context. If you don’t structure and redact that data early, your retrieval layer turns into a gossip engine with embeddings.
Retrieval Controls Are the Real Security Perimeter
If I had to pick one area where most RAG systems are underbuilt, it’s retrieval authorization.
Teams obsess over prompt engineering and then slap a half-baked metadata filter on top of a vector index. That’s like putting a bike lock on a bank vault.
You need retrieval controls that are boring, strict, and hard to bypass:
Document- and chunk-level ACLs
Every chunk should inherit access policy from its source document, tenant, user scope, and sensitivity class. Don’t rely on app-side filtering after retrieval. Enforce it in the retrieval path itself.
Tenant isolation
Cross-tenant leakage is the nightmare scenario. Separate indexes when risk justifies it. If you share infrastructure, your filtering logic needs tests that would make a paranoid auditor smile.
Metadata hard filters
Not “prefer same tenant.” Not “boost user department.” Hard filters. Required constraints.
Query intent policy
Some questions should never hit retrieval at all. “List all customers with overdue invoices and their contact details” shouldn’t be answered with a cheerful paragraph and a compliance incident.
For teams building custom models or sensitive internal copilots, this policy layer matters more than model choice. Qwen, GPT, Claude, Mistral — doesn’t matter. A polite model with bad retrieval controls is still dangerous.
Policy Enforcement Before Generation Is Where Adult Systems Live
This is the part hobby demos skip.
Before prompt assembly, run policy checks on:
- user identity
- tenant scope
- document classification
- requested action
- allowed fields
- tool permissions
- jurisdiction or compliance constraints
If policy denies access, the model shouldn’t get the data. Full stop.
Not “give it the data and ask it nicely not to mention private parts.”
We’ve all seen prompts like: Use the following context, but do not reveal any sensitive information. That’s not security. That’s wishful thinking in markdown.
For serious deployments, especially in regulated environments, this policy engine should be externalized and testable. Don’t hide your rules in a spaghetti nest of prompt templates and middleware if-statements.
That approach always works right up until Friday at 6:40 p.m.
Evals for Leakage: If You Don’t Test It, You Don’t Have It
Most teams don’t have a leakage problem.
They have a leakage measurement problem.
You need evals that specifically probe for:
- direct PII extraction
- paraphrased leakage
- cross-tenant retrieval
- indirect identity confirmation
- tool-based exfiltration
- prompt injection attempts that override masking or policy
- multilingual leakage
- OCR and malformed-document edge cases
Run these evals on every release. Not quarterly. Not “before the audit.” Every release.
A practical setup looks like this:
flowchart LR A[Ingestion tests] --> B[Retrieval authorization tests] B --> C[Prompt assembly policy tests] C --> D[Generation leakage evals] D --> E[Red-team adversarial prompts]
If you’re already investing in AI consulting, this is one of the highest-leverage places to spend time. Fancy demos impress buyers. Leakage evals keep buyers.
And yes, there’s a cost. You should estimate it. That’s true for infra, model calls, and the extra guardrails around them. If you need help scoping the economics, tools like our AI cost estimator are useful for getting realistic early numbers.
So What Is PII Masking Good For?
We’re not anti-masking.
We’re anti-delusion.
PII masking is still valuable for:
- final-response cleanup
- logs and observability pipelines
- staging and non-production datasets
- support dashboards
- analytics exports
- human review queues
That’s all real work. Important work.
But if you’re using output masking as your primary RAG security strategy, you’re putting a screen door on a submarine.
The right framing is:
- ingestion redaction reduces exposure
- retrieval controls prevent unauthorized access
- policy enforcement blocks unsafe prompt assembly and tool use
- output masking catches leftovers
That ordering matters.
A lot.
What We’d Build Instead
If we were hardening a RAG app handling customer records tomorrow, we’d do this:
- Classify documents and fields during ingestion.
- Strip or pseudonymize high-risk PII before embedding.
- Store raw sensitive values in a separate secured system of record.
- Tag chunks with tenant, role, document type, and sensitivity metadata.
- Enforce mandatory retrieval filters server-side.
- Run policy checks before prompt assembly and before any tool call.
- Keep prompts lean so unnecessary context never reaches the model.
- Apply output-stage masking as a final fallback.
- Run leakage evals continuously with adversarial test cases.
- Audit logs for retrieval decisions, not just model outputs.
That’s the blueprint.
If you’re building assistants in customer support, healthcare, finance, hospitality, or internal enterprise search, this is the difference between “works in demo” and “safe enough to ship.”
It’s also why privacy-sensitive deployments often benefit from on-device AI or tightly controlled architectures, depending on the use case. Sometimes the best way to reduce exfiltration risk is to stop sending data farther than it needs to go.
The Real Fix Isn’t Smarter Masking. It’s Better Boundaries.
That’s the whole story.
If you’re still asking why output-stage pii masking keeps failing in RAG security, the answer is brutally simple: because the model already saw the sensitive data, and the retrieval system already allowed it.
Masking at the end can still help. It just can’t undo bad architecture.
So start earlier. Redact at ingestion. Enforce policy before generation. Lock retrieval down like you mean it. Then test for leakage like your launch depends on it.
Because it does.
If you want help designing a RAG system that doesn’t casually leak private data under pressure, talk to us through Cropsly’s contact page. We’d rather help you fix the kitchen than sell you a nicer smoke detector.


