


Treat the Anthropic Ban as a Supply Chain Event
Hitesh Sondhi · June 16, 2026 · 12 min read
Your AI roadmap can become blocked by a policy fight you don't control.
A practical lesson from the Anthropic ban story isn't whether one model is safer, more aligned, too cautious, too political, or better behaved under jailbreak pressure. In an enterprise team, the sharper question is simpler: what happens when a model provider you're building around becomes unavailable, restricted, litigated, or politically radioactive?
TechCrunch’s June 15, 2026 reporting on the us government’s anthropic models ban argues the ban was never really about an AI jailbreak. Public framing may matter for politics, but enterprise architecture shouldn't depend on the public explanation being stable. When your production system needs Claude, Gemini, GPT, Llama, Qwen, or any single frontier model to behave exactly as it did last week, you don't have an AI strategy. What you have is a vendor dependency with a chat UI.
A dependency like that can be fine.
Pretending it isn't a dependency is the mistake.
The ban is a vendor-risk warning, not just an Anthropic story
A lot of teams will read this as a government procurement drama. In the story, the Department of Defense conflicts with a model vendor. Public officials argue about safeguards, model behavior, acceptable use, national security, or ideology. Lawyers get involved. Contractors get nervous.
That is the surface layer.
Enterprise lesson: frontier AI vendors now carry several risk categories at once: cloud vendor risk, data processor risk, policy vendor risk, safety gatekeeper risk, and geopolitical risk. Traditional SaaS procurement wasn't built for that bundle. Replacing a logging tool, payments provider, or CRM was painful, but the policy behavior of those systems usually didn't define your product behavior.
With AI, it can.
A support agent that refuses certain classes of requests because the upstream model policy changed has changed your workflow. A government restriction blocking a model family for a regulated customer changes your deployment plan. Vendor modifications to retention terms or inference routing change your compliance posture. A public dispute that makes the vendor unacceptable to one of your customers changes your sales cycle.
Supply chain issue is the better mental model than API outage. A factory doesn't treat a steel supplier as interchangeable if the supplier's alloy properties define the final product. Frontier models are now part of the product material.
Measure vendor risk the same way you measure uptime, latency, and gross margin impact. When the model disappears for 30 days, what breaks, what degrades, and what revenue is exposed?
Where single-model architectures fail
A boring failure pattern shows up again and again. A team starts with one model because it ships fastest. Prompts get tuned to that model. Evaluations are written against that model. Tool calls depend on that model's JSON habits. Human reviewers learn that model's failure modes. Product managers design UX around that model's tone.
Six months later, the "model adapter" is a thin wrapper around one API.
We see this in agent builds often enough that we now treat it as an architectural smell. Production agents, especially anything with tools, approvals, or compliance decisions, should put the model behind a policy and routing layer. The app shouldn't know whether the reasoning step came from Claude, GPT, Qwen, or a domain model unless there's a specific reason to expose it.
That matters especially for AI agents. Agents combine language, state, tools, memory, and permissions. Once tool execution enters the picture, model replacement isn't just a prompt migration. It becomes a behavioral migration.
The real lock-in hides in these places:
- Prompt idioms that only work on one model family
- Tool schemas that assume one vendor's function-calling behavior
- Safety behavior delegated fully to the model provider
- Evaluation sets that test happy paths but not vendor substitution
- Audit logs that don't capture model version, policy version, and routing decision
- Contracts that don't guarantee enough notice for material policy or availability changes
None of this means you need multi-model support on day one for every prototype. Production systems just need an exit ramp before procurement, compliance, or politics forces one.
A good test: can you run yesterday's production traces through another model and compare task success, policy violations, latency, and cost by tomorrow afternoon? Without that, you don't have a fallback. You have a rebuild.
The fallback tier shouldn't be theoretical
Most AI fallback plans are slideware. They say "use alternate model" and skip the parts that hurt.
A real fallback has three layers: model substitution, workflow degradation, and human escalation. All three matter because not every task survives model substitution cleanly.
In a contract analysis workflow, a frontier model might handle extraction, risk classification, and memo drafting. When your preferred model becomes unavailable, you might route extraction to another model, risk classification to a smaller custom classifier, and memo drafting to a human-assisted template. That isn't elegant, but it keeps the business process alive.
Voice systems are less forgiving. In voice AI, latency budgets punish naive fallback. A primary model that adds 800ms because traffic is rerouted to a different region makes users hear it. Fallback phrasing changes can break barge-in and confirmation flows. With RunHotel, our instinct is to keep the operational path narrow: the assistant should complete hotel tasks reliably, not improvise a new personality during a vendor incident.
Here's the architecture pattern we prefer for enterprise systems with real exposure:
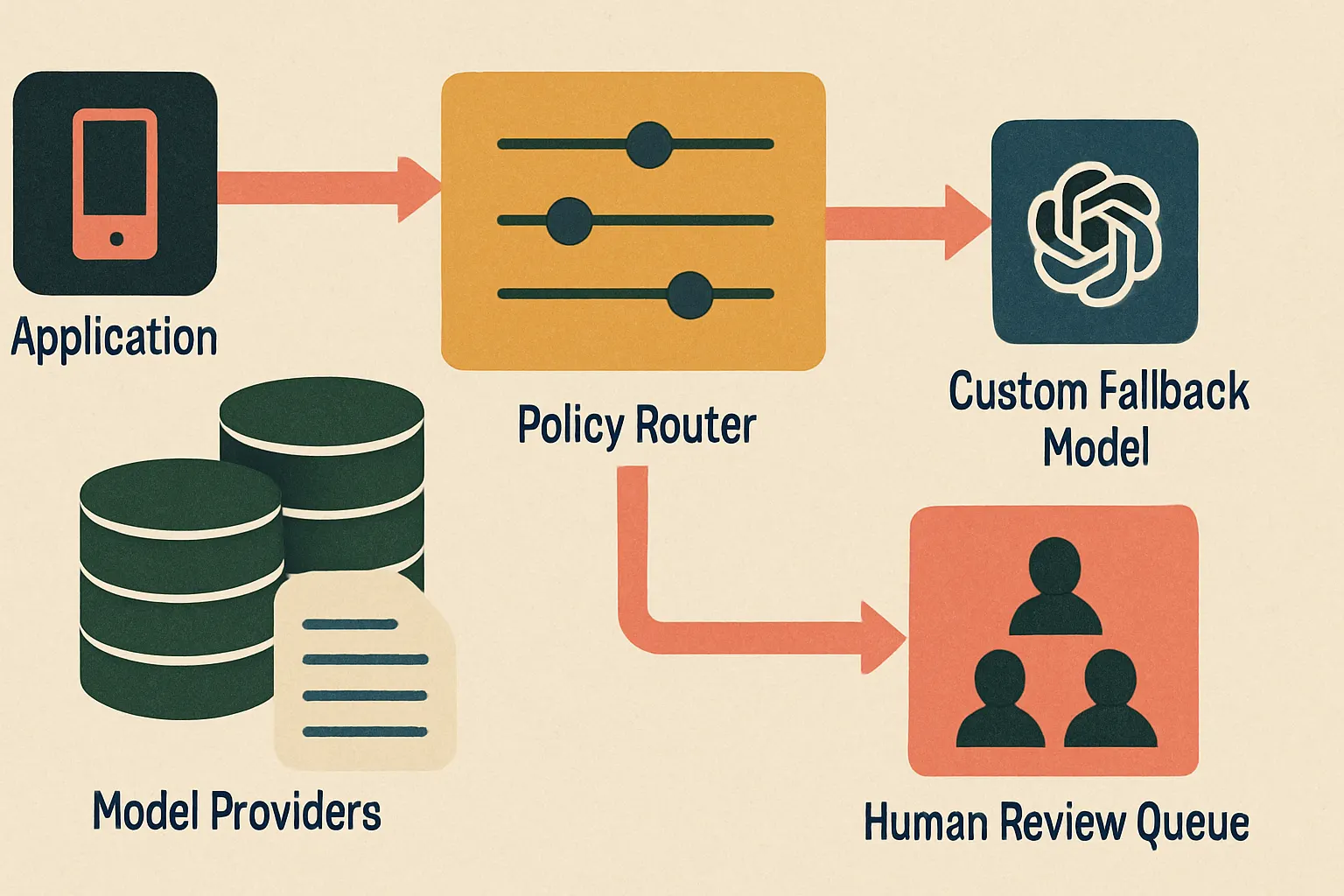
The policy router is the important part. A fancy load balancer isn't enough. Decisions should come from request class, data sensitivity, customer contract, jurisdiction, cost budget, latency budget, and allowed vendor list.
A good router knows that customer A permits Anthropic and OpenAI, customer B requires EU processing, customer C disallows external inference for regulated records, and customer D can use only an on-prem or VPC-hosted model. It also knows that summarization can degrade to a cheaper model, while legal approval can't.
Teams with strict data controls should treat on-device AI or private deployment as a risk reducer, not a branding feature. Running the strongest frontier reasoning model on a laptop or edge box isn't realistic, but deterministic workflows, wake-word handling, classification, redaction, or narrow command execution can stay local. That reduces the number of calls that ever need a frontier provider.
Build the fallback around business criticality, not model prestige. The expensive model should be reserved for tasks where it changes the outcome.
Compliance can't live inside the vendor's safety layer
One uncomfortable lesson from the Anthropic dispute is that vendor safety policy and customer compliance policy are not the same object.
They overlap, but they serve different principals. The vendor is protecting its platform, legal position, brand, and model behavior. Your side protects users, customers, contracts, regulators, and business continuity. When those incentives align, great. When they don't, you need your own control plane.
Enterprise AI needs a policy layer outside the model. That layer should decide what data can be sent, which model can process it, which tools can be called, what approvals are required, and what must be logged. The model can assist, but it shouldn't be the source of authority.
This matters in government, defense, healthcare, finance, hospitality, and any workflow where user trust depends on predictable constraints. A model refusal for something allowed by your policy needs a fallback path. A model allowing something prohibited by your policy needs a blocker before tools execute.
The pattern we recommend is plain:
- Classify the request before model selection
- Redact or transform sensitive fields before external inference
- Route by policy, not just cost or quality
- Validate outputs against schemas and business rules
- Gate risky tool calls through approval workflows
- Log prompt, model, version, policy decision, tool call, and final action
Heavy architecture sounds excessive until you compare it with the cost of reconstructing what happened during an incident. Auditability isn't paperwork. It's how you debug trust.
When you're already building with custom models, keep them close to the policy boundary. A small classifier trained for your regulated categories can be more valuable than a giant general model guessing whether a record is sensitive. We like frontier models for reasoning and language synthesis. Using them as the only compliance gate is the part we don't like.
Your compliance architecture should assume the vendor policy may change faster than your customer contracts.
Contract terms need to mention model behavior, not just uptime
Most vendor reviews still overweight uptime and underweight behavioral continuity.
Uptime matters, but a model can be "up" and still unusable for your workflow. The API returns 200. The output policy changed. The model version shifted. A refusal pattern expanded. A region became unavailable. A customer-specific restriction appeared. From your user's perspective, the system is broken.
Contracts and procurement checklists need to catch that.
Ask for notice periods around model deprecation, policy changes, data processing changes, region changes, and material behavior changes. Ask what happens if a government restriction, sanctions regime, litigation order, or internal acceptable-use decision affects your access. Ask whether your logs are enough to prove which model version processed which data.
Some vendors won't give you everything. That's normal. The goal isn't perfect protection. The goal is to price the dependency correctly.
When the vendor won't give notice, you need a stronger fallback. Missing region commitments mean you shouldn't use that vendor for data that requires them. Weak audit support means it shouldn't sit in the approval chain for regulated decisions. Safety behavior that can change without contractual consequence shouldn't be your only production guardrail.
A technical leader has to make the business call here. A frontier model might be the right choice even with weak contract terms if the task is low risk and high value. For a lower-value workflow with high regulatory exposure, it might be the wrong choice even if the demo looks excellent.
Use a cost model that includes replacement work. Our AI cost estimator is useful for inference spend, but vendor risk needs another line item: engineering weeks to migrate, validate, reapprove, and redeploy under pressure.
Your evaluation suite is your exit plan
Model portability needs evaluations before portability becomes urgent.
A fallback model won't behave the same way. That's expected. The question is whether it fails inside your acceptable envelope. Without evals, every migration becomes a taste test. Taste tests don't survive executive scrutiny or compliance review.
A useful enterprise eval suite has production traces, adversarial cases, policy boundary cases, latency budgets, cost budgets, and human-scored examples for subjective output. It also separates task success from style preference. We've seen teams reject a fallback because it sounded different, even though it completed the workflow correctly. That's bad prioritization.
Agentic systems need evals for tool-call accuracy and refusal correctness. A model that writes a better paragraph but calls the wrong tool is worse for production than a dull model that follows the policy. In workflow automation, boring is often the premium feature.
Run evals across at least three categories of models:
- Primary frontier provider
- Secondary frontier provider
- Smaller controlled model, either self-hosted, VPC-hosted, or domain-specific
The smaller model isn't there to win every benchmark. Its job is to keep the lights on for narrow tasks when the external dependency is constrained. In some Cropsly projects, especially where data locality or latency matters, we design the smaller model path from the start through on-device AI or private inference. It limits peak capability, but it cuts the blast radius.
Don't wait for a ban, lawsuit, procurement freeze, or terms change to learn your prompts only work with one model's quirks. Schedule portability tests the same way you schedule disaster recovery tests.
What engineering leaders should decide this month
The Anthropic ban shouldn't make you panic-switch vendors. A fast vendor change without architecture changes just moves the same risk to a different logo.
A better move is to classify your AI workloads by dependency risk. Put each workflow into one of four buckets: experimental, production low risk, production high risk, or regulated critical path. Then assign architecture requirements to the bucket.
Experimental systems can use one model and move fast. Production low-risk systems need trace logging and a named secondary provider. Production high-risk systems need policy routing, evals, and tested degradation paths. Regulated critical paths need stronger controls: data classification, external inference rules, human approval, model version auditability, and a viable non-frontier fallback for core operations.
This isn't overengineering. It's matching control cost to failure cost.
Founders have to ask whether model dependency affects enterprise sales. When a buyer asks what happens if your AI vendor loses eligibility, changes safety policy, or becomes unavailable in their jurisdiction, "we'll figure it out" is not a credible answer. A simple architecture diagram and tested fallback story can shorten that conversation.
Engineering leaders have to settle ownership. Vendor risk can't sit only with legal, and it can't sit only with ML. It touches product behavior, compliance, security, infrastructure, support, and customer commitments. Someone needs authority to say, "This workflow can't ship until fallback and audit are real."
Builders should start with the seams. Wrap provider calls. Store model and policy metadata. Keep prompts versioned. Separate policy checks from model output. Build evals from real traces. Make human escalation a designed path, not a support ticket category.
Need help designing that control plane? That's squarely in the work we do through AI consulting, agent architecture, backend engineering, and deployment planning. The useful deliverable isn't a vendor comparison spreadsheet. It's a production design that can survive a vendor becoming temporarily unusable without forcing your team into a weekend rewrite.


