


How to build an AI agent evaluation framework for production
Hitesh Sondhi · April 20, 2026 · 13 min read
We shipped an agent that looked brilliant in demos and then immediately embarrassed itself in the real world.
It could reason through a support workflow, call tools, summarize the result, and even sound confident while doing it. Then production happened. It picked the wrong tool, looped twice, invented a field that didn’t exist in the CRM, and confidently told the user the refund was processed when the API had returned a 403.
That’s the thing people don’t say loudly enough: most agent failures don’t look like failures. They look like plausible work.
And that’s why an AI agent evaluation framework matters. Not the fluffy version where you ask, “Did the answer seem good?” The production version, where you can tell whether the agent planned correctly, used tools correctly, stayed inside policy, finished the task, and did all of that at a cost and latency you can actually live with.
Key Takeaways
- A production-grade AI agent evaluation framework should measure more than final answer quality — planning, tool use, memory, safety, latency, and cost all matter.
- If you only evaluate outputs, your agent will lie to you with polished nonsense.
- The best setup combines code-based checks, model-based judges, and human review. Any one of those alone is incomplete.
- Offline evals catch regressions. Online evals catch reality.
- Start with 20 high-value task scenarios, not 2,000 mediocre test cases.
Why most agent evals are fake confidence
A lot of teams are still evaluating agents like they’re chatbots from 2023. They look at the final response, maybe score helpfulness, maybe ask another model to judge it, and call it a day.
That’s bad.
Agents fail in layers. The final answer might sound fine while the plan was flawed, the tool call schema was wrong, the retrieval was irrelevant, and the action should never have been taken in the first place. Evaluating only the final output is like judging a restaurant by the garnish while the chicken is still raw.
We’ve found that production agents need to be evaluated across at least four levels:
- Task outcome — did the agent actually complete the job?
- Process quality — did it reason, plan, and sequence actions well?
- Tool behavior — did it choose the right tools and use them correctly?
- Operational performance — was it safe, fast, and cheap enough?
IBM describes AI agent evaluation as assessing how an agent performs tasks, makes decisions, and interacts with tools and environments, which is directionally right and a useful baseline IBM. But in production, “assessing performance” is too broad to be useful unless you turn it into instrumentation and pass/fail rules.
Here’s the mental model we like: evaluating an agent is less like grading an essay and more like reviewing a flight recorder.
Something went wrong. Where? Why? Can it happen again?
What should an AI agent evaluation framework actually measure?
If your framework can’t tell you why the agent failed, it’s not a framework. It’s a vibes machine.
A solid AI agent evaluation framework should score the agent on multiple dimensions, with different graders for different failure modes.
1. Final task success
This is the obvious one, and it still matters. Did the agent resolve the ticket, book the room, generate the report, or update the database correctly?
For deterministic tasks, use code-based assertions. If the expected output is a JSON object, compare fields. If the task requires a database update, verify the side effect happened. If the booking should exist, query the system and check.
For open-ended tasks, you’ll need model-based or human grading too. But don’t start there if you can avoid it. Code-based checks are boring, brutal, and usually right.
2. Planning and reasoning quality
No, we don’t mean “read the chain of thought and vibe-check it.” That gets messy fast, and in many cases you shouldn’t rely on hidden reasoning traces anyway.
What you can evaluate is the observable plan:
- Did the agent decompose the task into sensible steps?
- Did it skip necessary steps?
- Did it branch when it hit uncertainty?
- Did it stop when it had enough evidence?
This is where trace-level evaluation matters. You want to inspect the sequence of actions, not just the final text.
3. Tool selection and tool execution
This is where many agents quietly die.
We’ve seen agents pick the second-best tool because the tool description was vague. We’ve seen them call the right tool with the wrong parameter names. We’ve seen them retry a failing tool three times because the model interpreted a permissions error as a transient outage.
Tool use needs its own metrics:
- Correct tool chosen
- Correct arguments passed
- Correct order of calls
- Recovery behavior on tool failure
- Number of unnecessary tool calls
If your agent has tools, your evals need traces. Full stop.
Here’s a simple way to think about the evaluation pipeline:
flowchart TD A[Test Scenario] --> B[Run Agent] B --> C[Capture Trace] C --> D[Code-Based Checks] C --> E[Model-Based Judge] C --> F[Human Review Queue] D --> G[Aggregate Scores] E --> G F --> G G --> H[Release or Block]
That diagram looks simple because it should be simple. If your eval architecture needs its own architect, you’ve overcooked it.
The three graders you actually need
There’s a reason serious teams converge on three kinds of evaluation: code-based, model-based, and human review. Each catches different classes of failure.
And yes, if you skip one, you’ll regret it.
Code-based graders: the reliable workhorses
These are your unit tests, assertions, schema checks, side-effect verifiers, latency thresholds, and policy rules.
They’re cheap, deterministic, and great for:
- JSON validity
- Required fields present
- Tool arguments match schema
- API side effects occurred
- No forbidden actions taken
- Latency under threshold
- Cost under threshold
They’re terrible at nuance, but that’s fine. Not everything needs nuance.
Model-based judges: useful, slippery, and easy to abuse
LLM-as-a-judge works well for fuzzy criteria like relevance, coherence, instruction adherence, or whether a summary preserved key facts. Research from OpenAI found that model graders can be effective when carefully designed and calibrated, especially for tasks where exact matching is too brittle OpenAI.
But here’s the hot take: model judges are overrated when teams use them as a shortcut for thinking.
If your rubric is vague, your judge will be vague. If your examples are weak, your scores will drift. If the judge model changes, your benchmark can quietly move under your feet. That’s not evaluation. That’s astrology with tokens.
Use model-based judges with:
- explicit rubrics
- anchor examples
- periodic human calibration
- versioned prompts and judge models
Human review: expensive, annoying, unavoidable
Nobody wants to hear this, but some failure modes are too contextual for automation. Policy edge cases, brand-sensitive responses, ambiguous user intent, and “technically correct but obviously wrong” outputs still need people.
Human review is where you catch the weird stuff.
Here’s where it gets weird.
Sometimes your best eval cases come from production incidents, not synthetic benchmarks. The customer who phrased a request in a bizarre but valid way. The hotel guest who switched languages halfway through a voice request. The user who asked the agent to do two things, one allowed and one forbidden, in the same sentence.
If you’re building AI agents or voice AI, those edge cases are the whole game.
Build your dataset like you mean it
Most eval datasets are bloated junk drawers. Hundreds of low-signal examples, barely maintained, with no clear mapping to business risk.
We’d rather have 50 sharp knives than 500 plastic forks.
Start with a test set that reflects real production risk:
Tier 1: Golden paths
These are your core workflows. High frequency, high business value, low ambiguity.
Examples:
- “Cancel reservation and confirm refund status”
- “Create support ticket with correct priority”
- “Summarize account history using CRM data”
Tier 2: Edge cases
These are rare but painful.
Examples:
- Missing tool response fields
- Contradictory user instructions
- Partial permissions
- Multi-step tasks with one failing dependency
Tier 3: Adversarial and safety cases
This is where you test jailbreaks, prompt injection, policy violations, and unauthorized actions.
OWASP’s guidance on LLM application risks is useful here, especially around prompt injection, data leakage, and excessive agency OWASP.
A good dataset isn’t just labeled by task. It’s labeled by failure mode:
- reasoning failure
- retrieval failure
- tool misuse
- policy violation
- latency breach
- cost blowout
That last one gets ignored way too often.
If your agent completes the task in 19 tool calls and 22 seconds, congratulations, you built a very expensive intern.
The metrics that matter in production
People love abstract metrics because they look nice in dashboards. Production doesn’t care.
Your AI agent evaluation framework should include metrics that map to operational reality:
Quality metrics
- Task success rate
- Exact match or schema match
- Groundedness / factual consistency
- Instruction adherence
- Tool correctness
- Recovery success after failure
Process metrics
- Steps per task
- Unnecessary tool calls
- Retry count
- Planning efficiency
- Context usage quality
Operational metrics
- End-to-end latency
- p95 / p99 latency
- Cost per successful task
- Token usage per task
- Error rate by tool and scenario
Safety metrics
- Policy violation rate
- Unauthorized action attempts
- Prompt injection susceptibility
- Sensitive data exposure
Google’s Vertex AI evaluation docs and agent evaluation materials are useful references for framing task success, tool use, and trajectory-level analysis in agent systems Google Cloud.
But don’t blindly copy vendor scorecards. Their framework has to fit every customer. Yours needs to fit your actual failure budget.
Offline evals are necessary. Online evals are where the bodies are buried.
Offline evals are how you prevent obvious regressions before release. They belong in CI. Every prompt change, tool schema change, model swap, or memory tweak should trigger them.
But offline evals have a blind spot: users are creative in the worst possible ways.
So you also need online evaluation:
- sampled production traces
- shadow deployments
- A/B tests
- canary releases
- human review queues for risky actions
- runtime guardrails and alerts
We learned this the hard way on voice systems. Audio quality shifts, accents vary, background noise changes, and suddenly the agent that passed your lab tests starts acting like it had two hours of sleep and one broken headphone.
If you’re deploying on-device AI or products like RunHotel, this gets even sharper because network assumptions, hardware constraints, and user behavior all pile onto the same system.
Here’s a visual for the split:
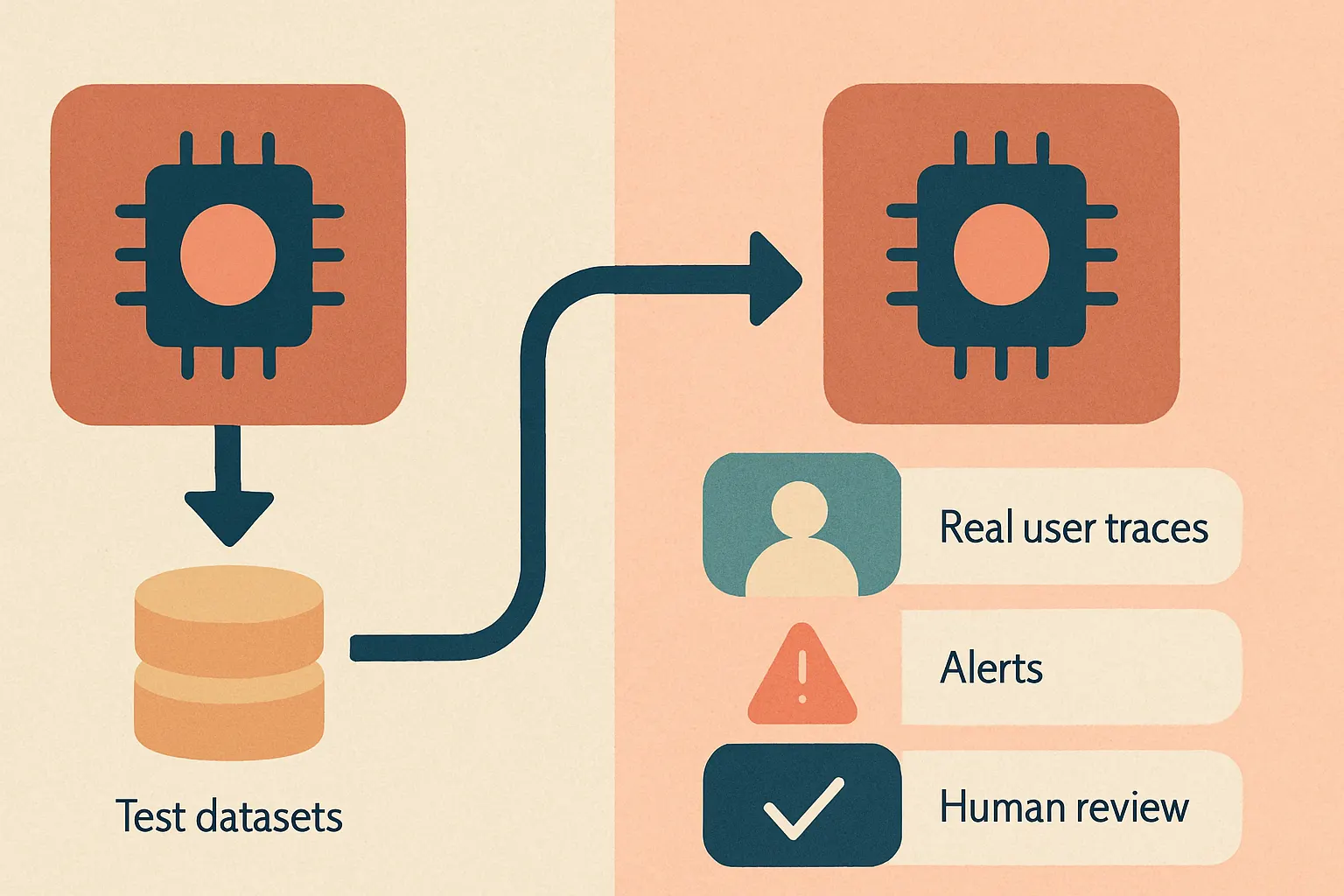
Offline tells you whether the build is broken.
Online tells you whether reality is broken.
A practical architecture for production evals
You do not need a giant platform on day one. You need a pipeline that’s boring enough to trust.
A practical setup looks like this:
Step 1: Log structured traces
Capture:
- user input
- system prompt version
- model version
- tool calls and arguments
- tool responses
- intermediate decisions if exposed
- final output
- latency and token usage
- outcome labels if available
Without traces, you’re guessing.
Step 2: Create scenario-based test suites
Group by workflow and risk. Don’t just have one giant benchmark. Split by:
- support
- sales ops
- booking
- compliance
- internal knowledge tasks
Step 3: Run multiple graders
Use code checks first, model judges second, humans for disputes and sensitive cases.
We also recommend storing grader disagreement. When code says pass and the judge says fail, that’s usually a sign your rubric is muddy or your test case is underspecified.
Step 4: Define release gates
Examples:
- task success must not drop more than X from baseline
- policy violations must be zero on critical scenarios
- p95 latency must stay under threshold
- cost per successful task must remain within budget
No release without gates. Otherwise “evaluation” becomes decorative.
Step 5: Feed production failures back into the benchmark
This is the compounding loop. Every nasty real-world incident becomes a permanent test case.
That’s how your AI agent evaluation framework gets smarter over time instead of becoming a stale spreadsheet nobody trusts.
Common mistakes that waste months
We’ve seen these enough times to be rude about them.
Mistake 1: Treating eval as a one-time project
It’s not. It’s a living system tied to prompts, tools, models, policies, and product changes.
Mistake 2: Only measuring answer quality
If the agent used the wrong tool, exposed sensitive data, or took 14 seconds too long, the answer quality score won’t save you.
Mistake 3: No business-level metric
You don’t just need “score 0.82.” You need “resolved ticket correctly,” “reduced human escalations,” or “completed booking without agent intervention.”
Mistake 4: Ignoring cost
This one is especially funny because teams notice it only after a large invoice arrives.
If you’re estimating what an agent workflow will cost before rollout, use something like our AI cost estimator. It’s much cheaper than learning by accident.
Mistake 5: Overfitting to the benchmark
Congrats, your agent memorized the exam. Production will now introduce new questions.
FAQ
What is an AI agent evaluation framework?
An AI agent evaluation framework is a system for measuring how well an agent completes tasks, uses tools, makes decisions, follows policy, and performs operationally in production. The useful version includes datasets, traces, graders, metrics, and release gates.
How is agent evaluation different from LLM evaluation?
Agent evaluation is broader because the model isn’t just generating text — it’s planning, calling tools, handling memory, and sometimes taking actions in external systems. That means you need to evaluate trajectories and side effects, not just outputs.
Should we use LLM-as-a-judge for agent evals?
Yes, but carefully. It’s good for fuzzy quality checks, but it should be calibrated against human review and backed by deterministic checks wherever possible.
What metrics should we track first?
Start with task success rate, tool correctness, policy violations, p95 latency, and cost per successful task. Those five will tell you more than a giant dashboard full of decorative nonsense.
How often should we run evaluations?
Run offline evals on every meaningful change and review online traces continuously. If your agent changes weekly, your evals should too.
If we were building this from scratch tomorrow
We’d start with 20 to 50 high-risk scenarios, full trace logging, code-based assertions, one judge rubric for fuzzy quality, and a weekly human review pass on sampled failures.
That’s enough to get signal fast.
Then we’d add release gates, online sampling, and a feedback loop from incidents into the benchmark. If the use case involved regulated workflows, external actions, or customer-facing voice, we’d tighten the screws immediately and probably bring in AI consulting or build domain-specific custom models where generic behavior kept wobbling.
You don’t need a perfect system.
You need one that catches the expensive mistakes before your users do.
If you’re building agents and want help designing an evaluation stack that survives production, talk to us through Cropsly’s contact page. We’ve spent enough time cleaning up agent messes to know where the fires usually start.
And they usually start right after someone says, “The demo looked great.”


